随着现在开源大模型的崛起,在自己的的电脑上跑大模型,实现GPT的功能已经很方便了。工作时间长了,我们总会收集很多资料,虽然经常看的频率不会很频繁,但是又是舍不得删除,万一什么时候用的到。久而久之,我们会完全忘记这些资料的内容。今天我们用本地电脑搭建一个AI环境来解决这个问题。
为什么用本地电脑跑大模型呢,不会很耗电脑的CPU和GPU吗?会有影响。很多事情怎么做,取决于我们的目的。我们的目的不是为了频繁的使用AI大模型,重点是先搭建一个环境,而且免费,同时满足隐私需求,不会把自己的资料暴露在互联网。在知识库里面不断的补充新资料,给AI投喂足够多的文档,让他成为一个垂直领域的专业助手。
根据这个场景,我们可以用最新开源的llama3或者阿里巴巴的通义千问来作为基础大模型。如果资料以英文为主,推荐用llama3。如果资料以中文为主,推荐以中文训练的千问(qwen)。模型数量选择基础版,不需要上高配,运行平台选Ollama,知识库软件用AnythingLLM。
Ollama安装
首先在 ollama.com 官网上下载软件。
安装完成后,打开命令行或终端,选择最新开源的llama3。对于一般需求,下载基础大模型8B版本即可,70B需要单独购置GPU来实现。然后下载千问qwen 7B版本。很多人会纠结llama3/llama2的中文微调版本或者国内大模型。根据我的测试结果,国内大模型更适合中文,毕竟一个是微调,一个是直接用中文训练的,还是有一定差距,而且微调版本质量参差不齐。
终端输入代码,下载大模型:
ollama run llama3:8b
ollama run qwen:7b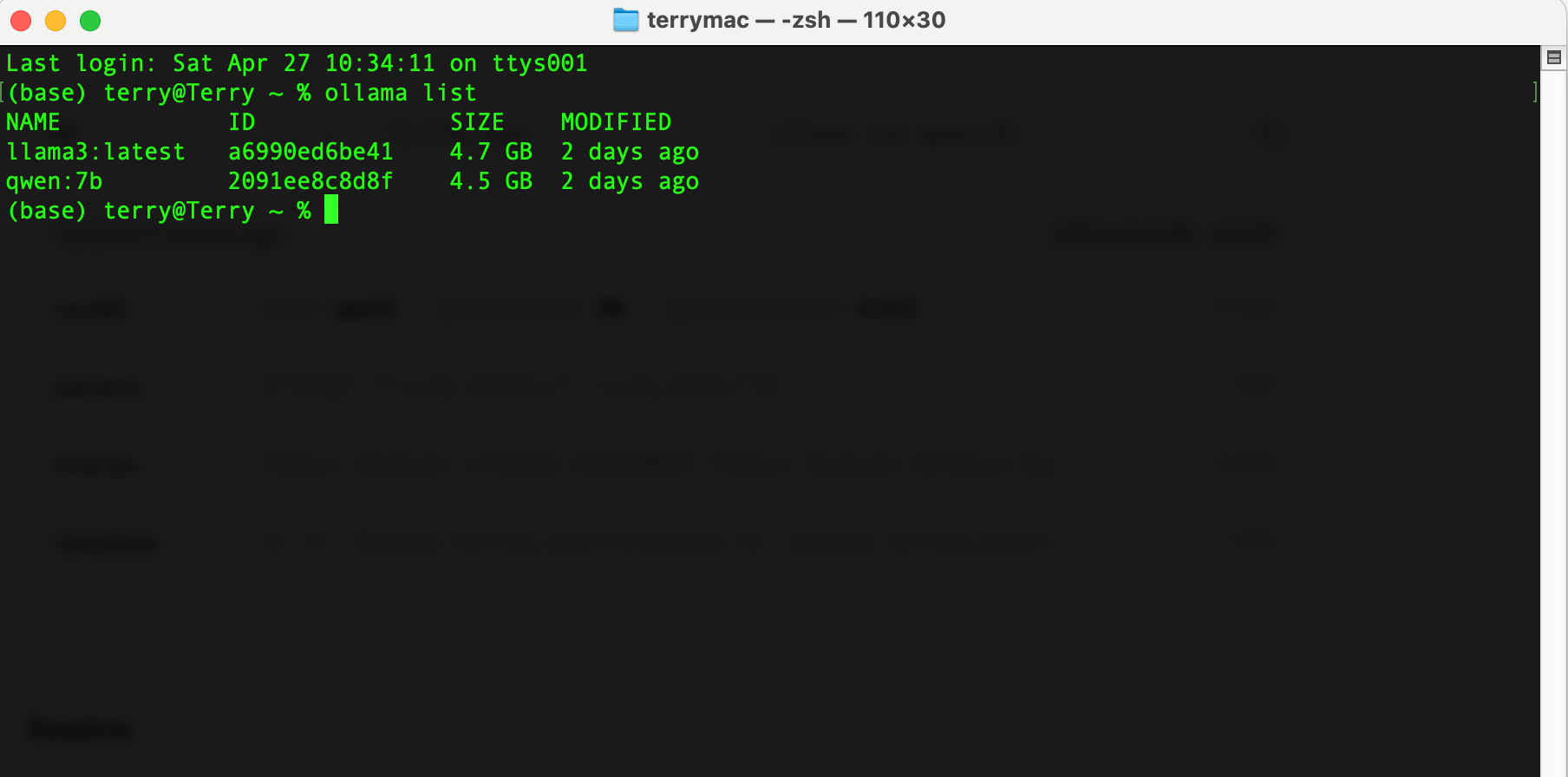
如果我们想在web ui 上直接使用,可以安装Open WebUI。因为需要另外安装docker环境,这里不做介绍。
AnythingLLM安装
在官网下载:https://useanything.com/
由于是AnythingLLM是以软件的形式呈现,对非技术人员比较友好。
AnythingLLM支持的功能挺多,虽然是本地知识库,但是可以对接谷歌api进行搜索,也可以对接openai api连接 AI agent。它的workspace功能对于分类不同领域的文件很方便,同时有缓存,下次打开软件,可以保留之前的对话,各种功能都很适合做一个隐私的本地知识库。
如何使用
Ollama+AnythingLLM配置
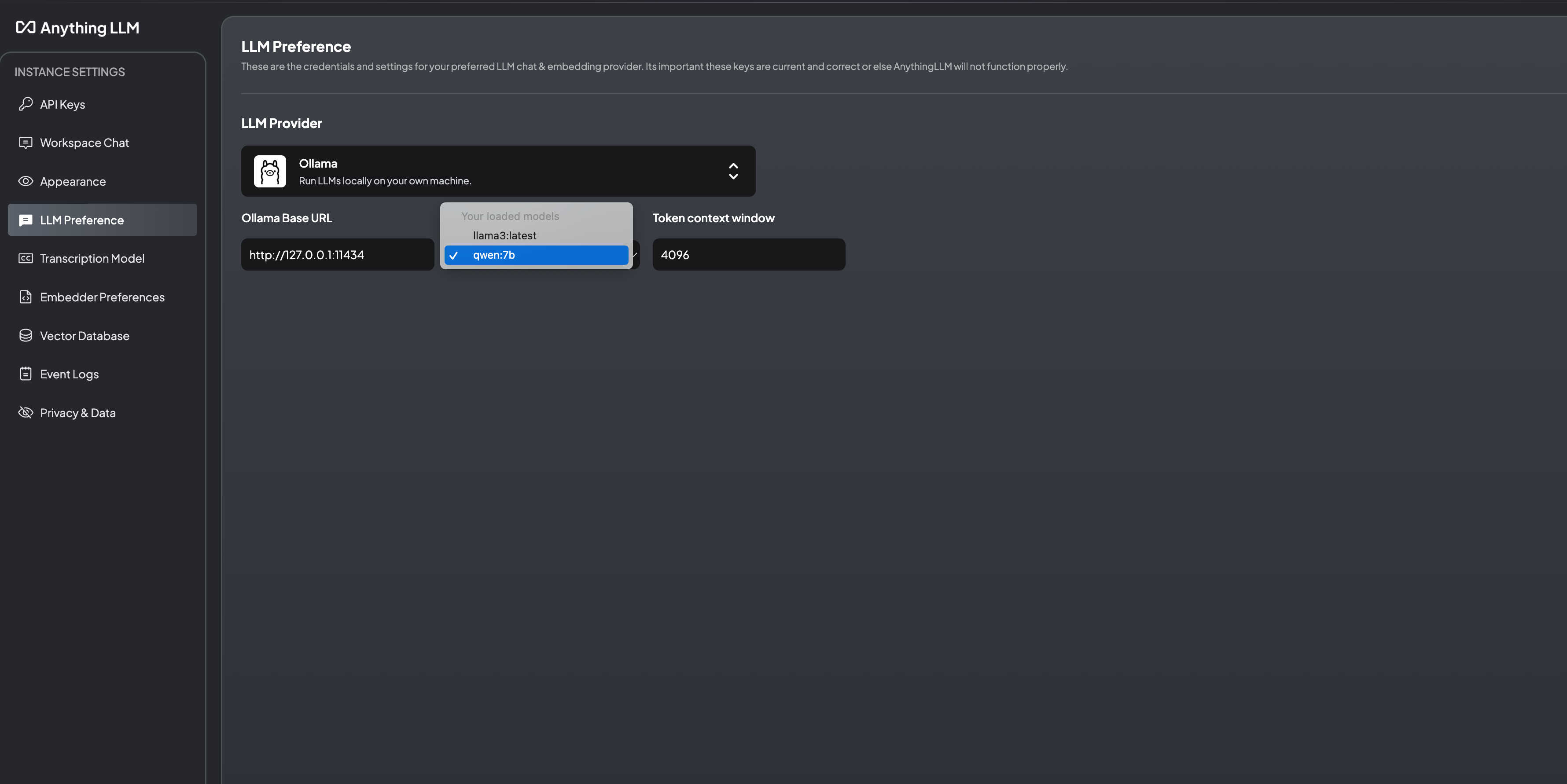
在运行之前,我们先打开ollama软件,让大模型的环境先在后台随时等待调用。第一次使用AnythingLLM的时候,需要简单配置下接口,编译方式和数据库。在LLM设置界面选择Ollama平台,同时输入Ollama的端口:http://host.docker.internal:11434
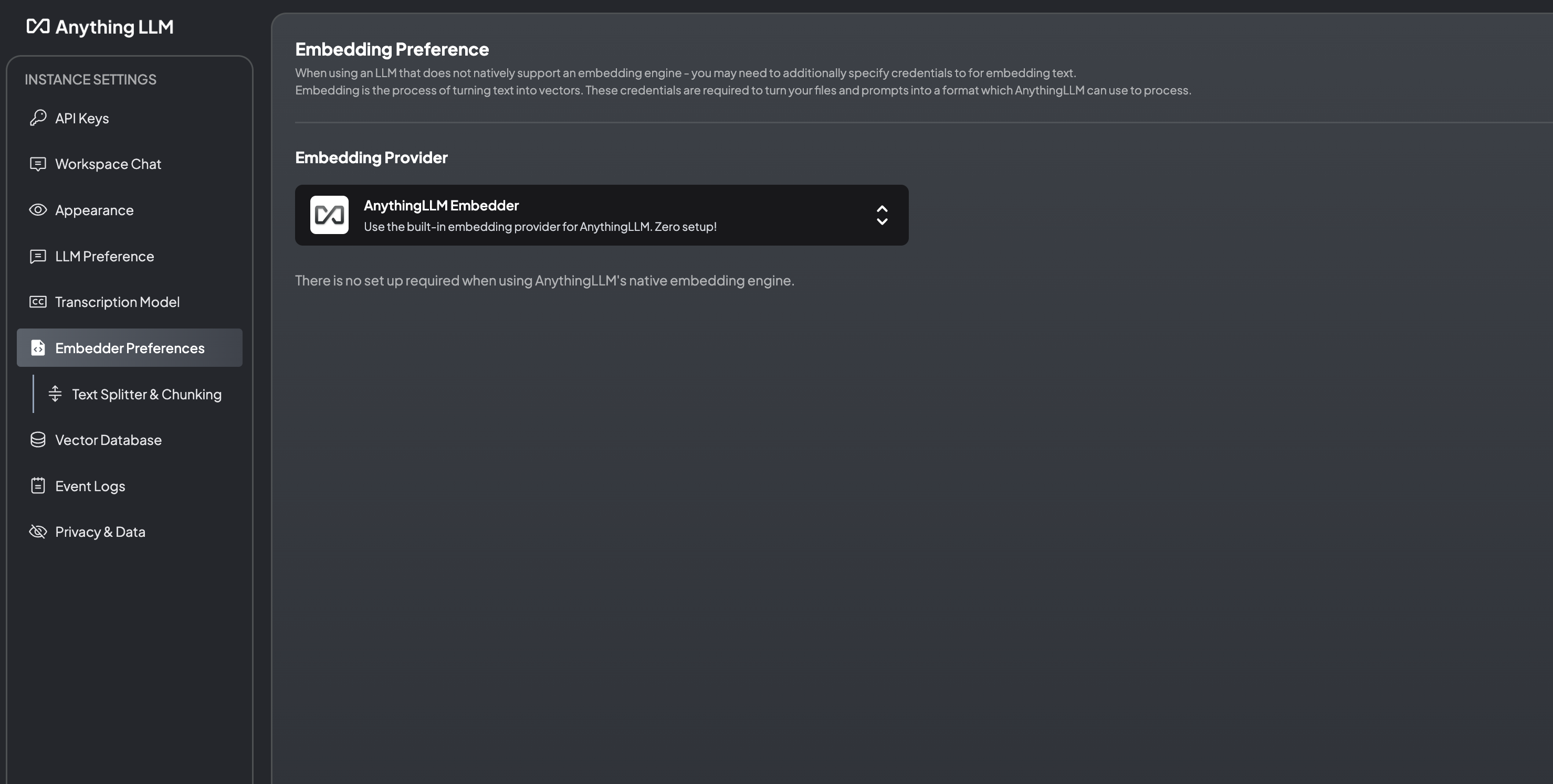
Embedder配置默认选择AnythingLLM,数据库默认选择LanceDB。嵌入的大模型可以在应对不同语言文档的时候重新选择。我下载了很多大模型,最后就保留了llama3和千问,支持国产大模型。
知识库配置
导入pdf资料文件,然后进行向量化。
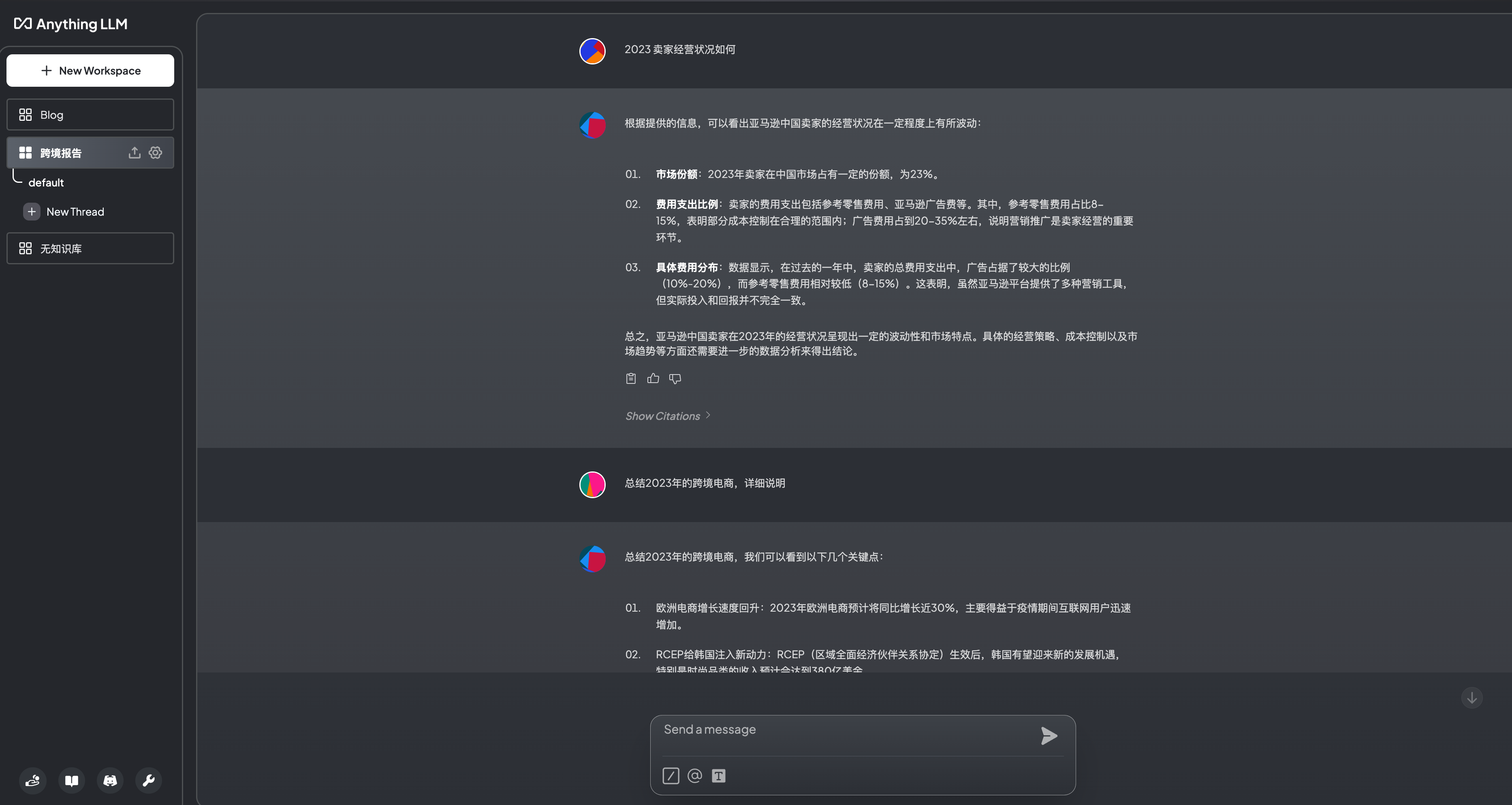
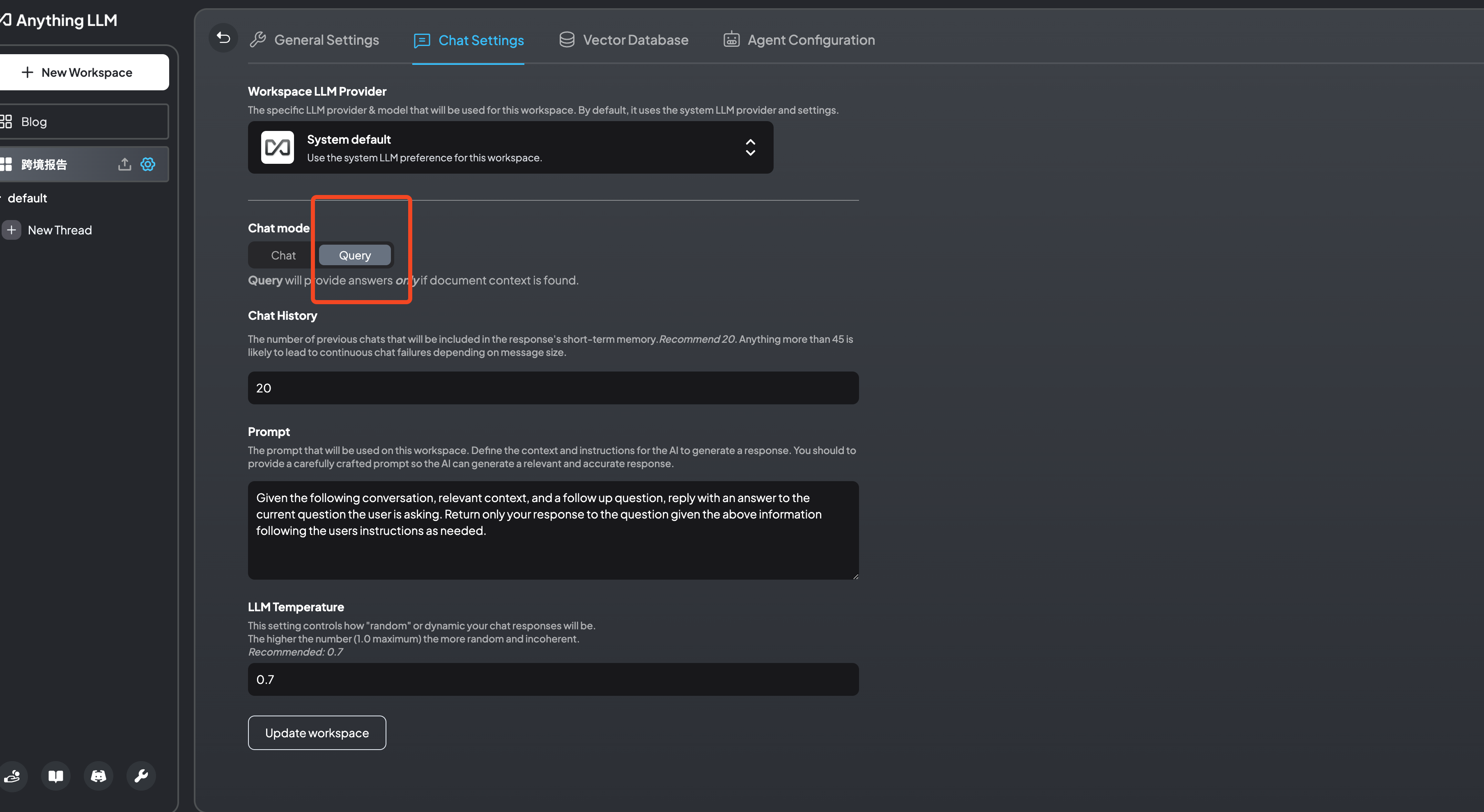
为了提高AI回复的相关性,可以选择chat mode的Query,意思是ai只从提供的知识库中寻找答案。实际测试中,在不依赖知识库的情况下,千问模型还是会根据本身的知识储备给一个泛泛的回答,llama3是直接不提供答案。现在虽然技术门槛降低了,但是要达到很好的效果还是需要微调,因为我们应用的场景比较明确,即使有一些bug,也不影响使用。
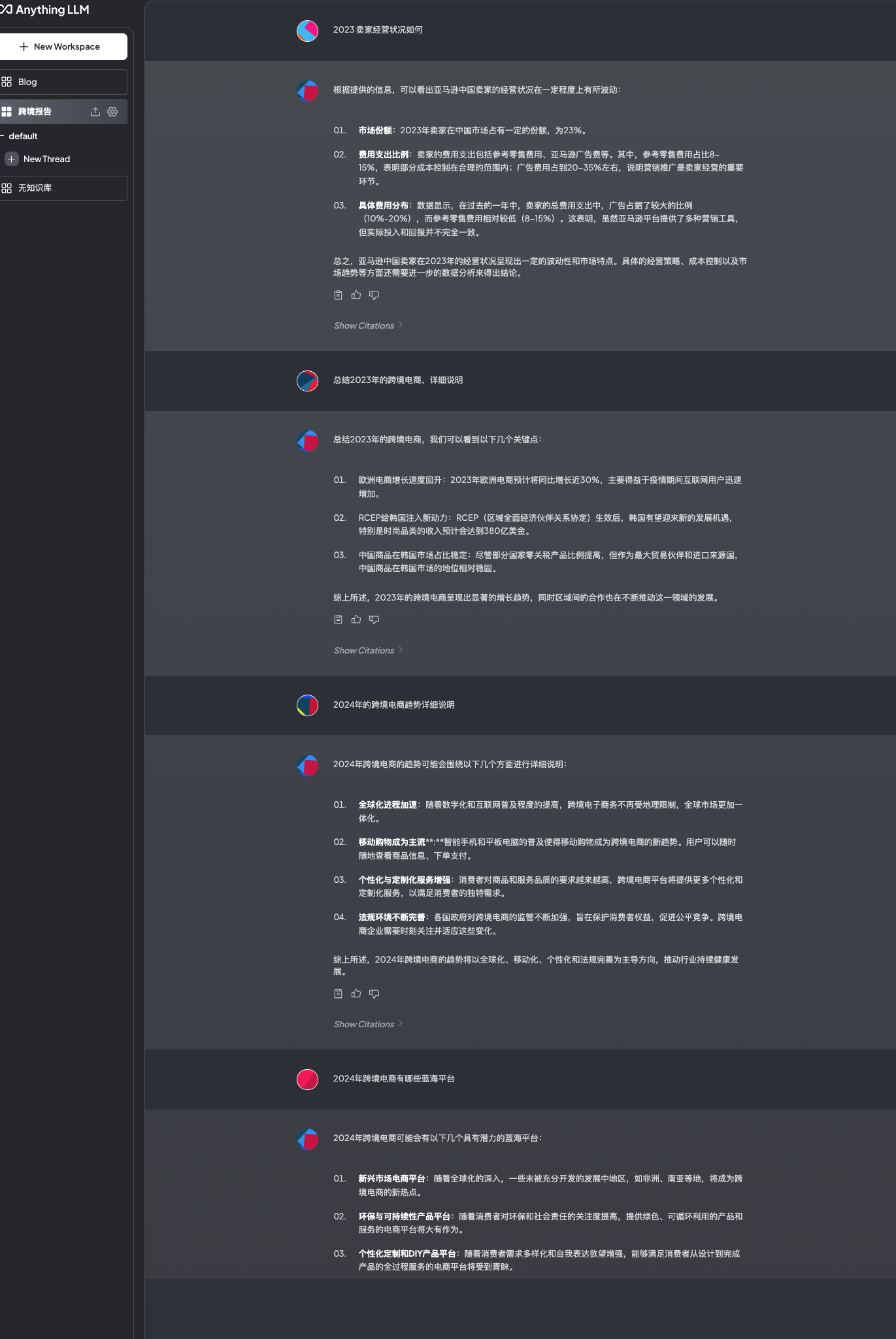
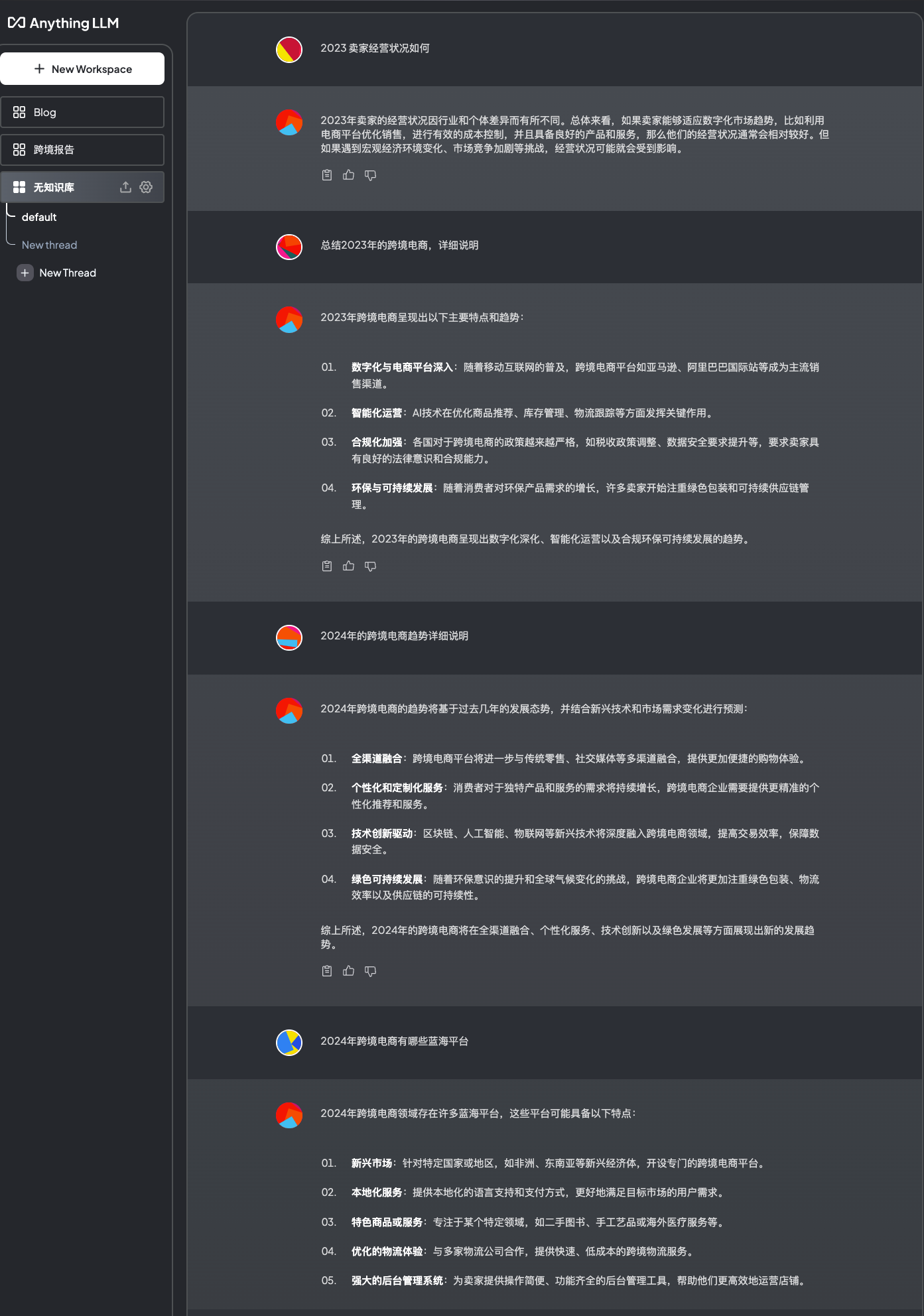
部署成功了,我测试了两个版本,一个是依赖知识库的workspace“跨境报告”,一个是不依赖知识库的workspace“无知识库”。可以看出“跨境报告”可以显示出引文的内容,回答有具体的数字。而“无知识库”只是一个开放式的回答。
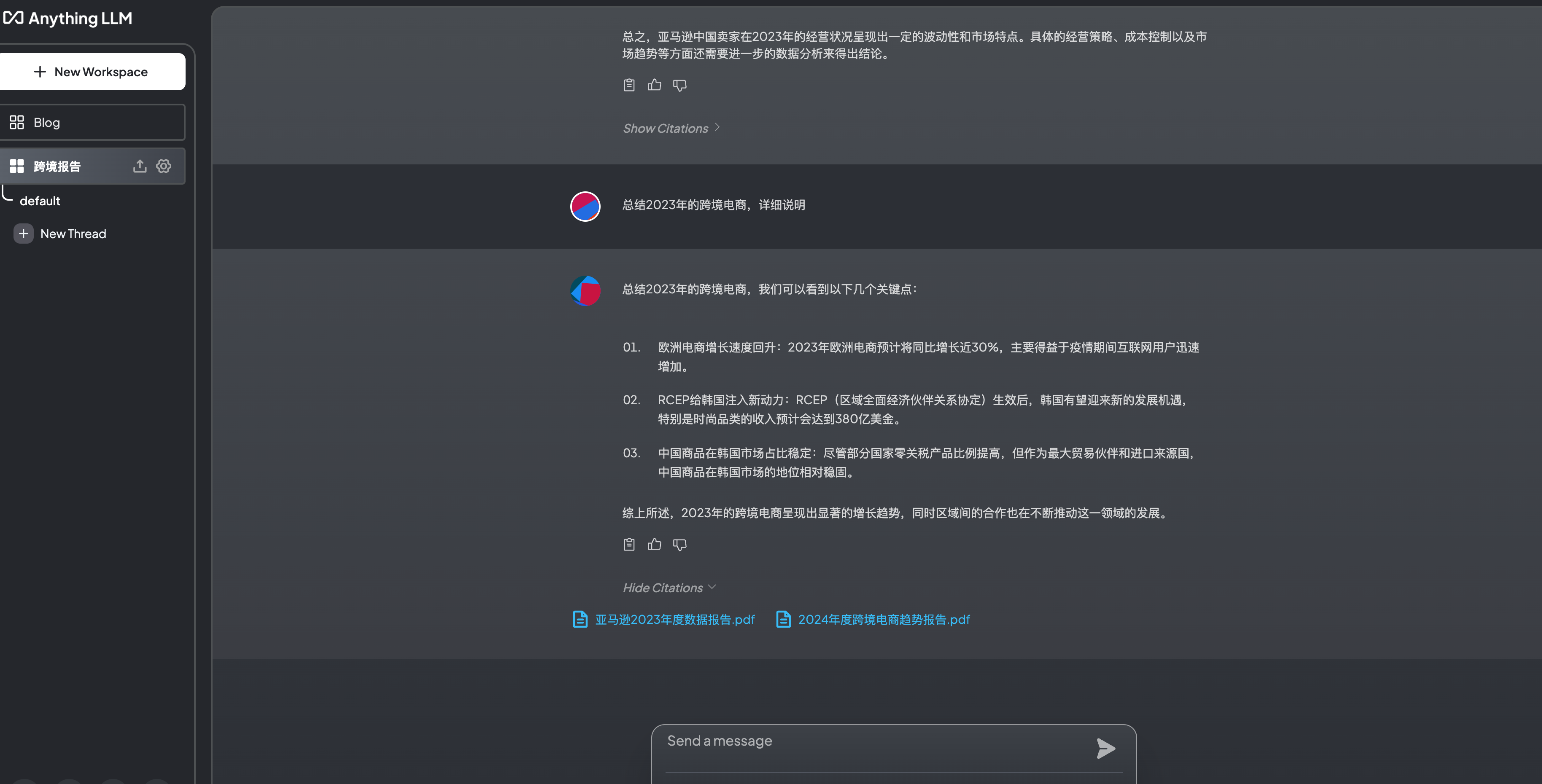
对比
下面是两个版本的回答,大家可以自己体会一下,搭建自己的知识库测试一下。如果有更好的解决方案,可以随时找我讨论。