机器学习和线性回归的理论部分已经总结到思维导图。下面结合一组实例用Python进行分析。结合机器学习的步骤,分析如下:
1 提出问题
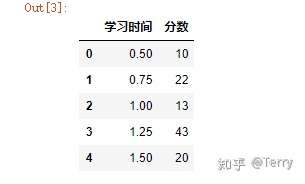
建立一组模拟数据,分析学习时间和考试分数的相关性。用有序字典建立数据集,并查看数据
*#数据集*``examDict``**=**``{ '学习时间':[0.50,0.75,1.00,1.25,1.50,1.75,1.75,2.00,2.25, 2.50,2.75,3.00,3.25,3.50,4.00,4.25,4.50,4.75,5.00,5.50], '分数': [10, 22, 13, 43, 20, 22, 33, 50, 62, 48, 55, 75, 62, 73, 81, 76, 64, 82, 90, 93] } examOrderDict``**=**``OrderedDict(examDict) examDf``**=**``pd``**.**``DataFrame(examOrderDict) examDf``**.**``head()
2 理解数据
提取特征和标签,并绘制散点图,初步判断两组数据是否有线性相关。这里需要导入matplotlib进行可视化分析。
exam_X``**=**``examDf``**.**``loc[:,'学习时间'] exam_Y``**=**``examDf``**.**``loc[:,'分数'] ``**import**`` matplotlib.pyplot ``**as**`` plt plt``**.**``scatter(exam_X,exam_Y,color``**=**``'b',label``**=**``'exam data') plt``**.**``xlabel('Hours') plt``**.**``ylabel('Score') plt``**.**``show()
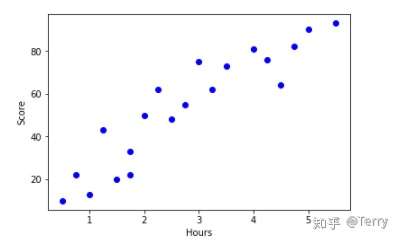
通过散点图,可以看出,两组数据大致符合线性相关的关系。接下来,我们进行下一步。(本来下一步应该是数据清洗,由于此处数据样本较少,不涉及到清洗,因此略过。)
3 构建模型
根据train test split 函数,我们建立样本特征和标签,并指定训练数据占比80%。
**from**`` sklearn.cross_validation ``**import**`` train_test_split X_train,X_test,Y_train,Y_test``**=**``train_test_split(exam_X,exam_Y,train_size``**=.**``8) ``**print**``('原始数据特征:',exam_X``**.**``shape, '训练数据特征:',X_train``**.**``shape, '测试数据特征:',X_test``**.**``shape) ``**print**``('原始数据标签:',exam_Y``**.**``shape, '训练数据标签:',Y_train``**.**``shape, '测试数据标签:',Y_test``**.**``shape)
输出结果为:
原始数据特征: (20,) 训练数据特征: (16,) 测试数据特征: (4,)
原始数据标签: (20,) 训练数据标签: (16,) 测试数据标签: (4,)
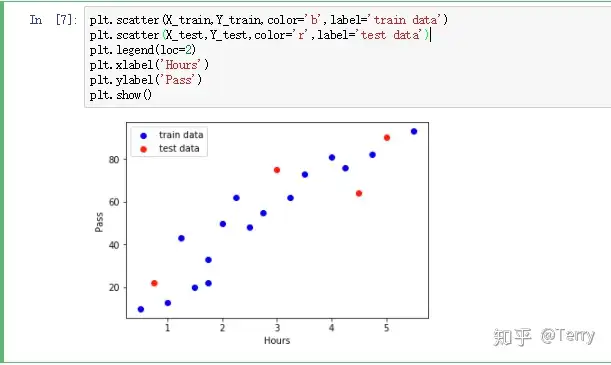
再次绘制散点图,查看数据:
plt``**.**``scatter(X_train,Y_train,color``**=**``'b',label``**=**``'train data') plt``**.**``scatter(X_test,Y_test,color``**=**``'r',label``**=**``'test data') plt``**.**``legend(loc``**=**``2) plt``**.**``xlabel('Hours') plt``**.**``ylabel('Pass') plt``**.**``show()
接着,创建线性回归的模型,并求出截距,回归系数和决定系数R平方。
X_train``**=**``X_train``**.**``values``**.**``reshape(``**-**``1,1) X_test``**=**``X_test``**.**``values``**.**``reshape(``**-**``1,1) ``**from**`` sklearn.linear_model ``**import**`` LinearRegression model``**=**``LinearRegression() model``**.**``fit(X_train,Y_train)
LinearRegression(copy_X=True, fit_intercept=True, n_jobs=1, normalize=False)
a``**=**``model``**.**``intercept_ b``**=**``model``**.**``coef_ ``**print**``('最佳拟合线:截距a=',a,',回归系数b=',b)
最佳拟合线:截距a= 6.018987341772139 ,回归系数b= [17.09873418]
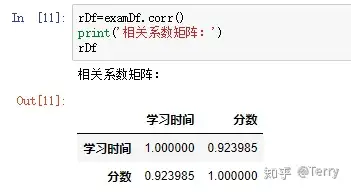
rDf``**=**``examDf``**.**``corr() ``**print**``('相关系数矩阵:') rDf
model``**.**``score(X_test,Y_test)

4 评估模型
plt``**.**``scatter(X_train,Y_train,color``**=**``'blue',label``**=**``'train data') Y_train_pred``**=**``model``**.**``predict(X_train) plt``**.**``plot(X_train,Y_train_pred,color``**=**``'black',linewidth``**=**``3,label``**=**``'best line') plt``**.**``scatter(X_test,Y_test,color``**=**``'red',label``**=**``'test data') plt``**.**``legend(loc``**=**``2) plt``**.**``xlabel('Hours') plt``**.**``ylabel('Score') plt``**.**``show()
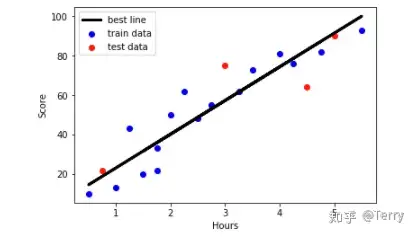
通过决定系数,我们可以得知,两组数据的拟合程度还算可以,有一定的可信程度。这就是一个简单的线性回归的例子,他们反映的只是两组数据数学上的的相关性,并不一定说明他们有必然的决定关系。更深度的关系,还需要结合其他因素进行分析。