1. 提出问题
这次,我的客户是一个新成立的电影制作公司。他们将制作一部新电影,并确保电影能够成功,从而立足市场。客户希望我们咨询公司可以帮助他们了解电影市场趋势,做出正确的决策。他们提供了三个研究领域:
- 问题 1: 电影类型是如何随着时间的推移发生变化的?
- 问题 2: Universal Pictures 和 Paramount Pictures 之间的对比情况如何?
- 问题 3: 改编电影和原创电影的对比情况如何?
2. 理解数据
2.1 采集数据
TMDB 5000 Movie Datasetwww.kaggle.com/tmdb/tmdb-movie-metadata
The Movie Database (TMDb)www.themoviedb.org/?language=en
这里直接选用Kaggle提供的数据
2.2 导入数据
`#忽略警告提示**import** warnings
warnings**.**filterwarnings(‘ignore’)
*#导入包*importnumpyasnpimportpandasaspdimportmatplotlib.pyplotas“ plt
**import** seaborn **as** sns
sns**.**set_style(‘whitegrid’)
**%**matplotlib inline
**import** json
*#导入数据*movies**=**pd**.**read_csv(’./tmdb_5000_movies.csv’)
credits**=**pd**.**read_csv(’./tmdb_5000_credits.csv’)
**print**(‘movies数据的行和列’,movies**.**shape)
**print**(‘credits数据的行和列’,credits**.**shape)
movies数据的行和列 (4803, 20)
credits数据的行和列 (4803, 4)
*# 将json转换成字符串**# genres *movies['genres']=movies['genres'].apply(json.loads) forindex,iin zip(movies.index,movies['genres']): list1=[] forjin range(len(i)): list1.append((i[j]['name'])) movies.loc[index,'genres']=“str(list1)
*# keywords *movies[‘keywords’]**=**movies[‘keywords’]**.**apply(json**.**loads)
**for** index,i **in** zip(movies**.**index,movies[‘keywords’]):
list1**=**[]
**for** j **in** range(len(i)):
list1**.**append((i[j][‘name’]))
movies**.**loc[index,‘keywords’]**=**str(list1)
*# production_companies *movies[‘production_companies’]**=**movies[‘production_companies’]**.**apply(json**.**loads)
**for** index,i **in** zip(movies**.**index,movies[‘production_companies’]):
list1**=**[]
**for** j **in** range(len(i)):
list1**.**append((i[j][‘name’]))
movies**.**loc[index,‘production_companies’]**=**str(list1)
*# production_countries *movies[‘production_countries’]**=**movies[‘production_countries’]**.**apply(json**.**loads)
**for** index,i **in** zip(movies**.**index,movies[‘production_countries’]):
list1**=**[]
**for** j **in** range(len(i)):
list1**.**append((i[j][‘name’]))
movies**.**loc[index,‘production_countries’]**=**str(list1)
*# cast *credits[‘cast’]**=**credits[‘cast’]**.**apply(json**.**loads)
**for** index,i **in** zip(credits**.**index,credits[‘cast’]):
list1**=**[]
**for** j **in** range(len(i)):
list1**.**append((i[j][‘name’]))
credits**.**loc[index,‘cast’]**=**str(list1)
*# crew *credits[‘crew’]**=**credits[‘crew’]**.**apply(json**.**loads)
**def** **director**(x):
**for** i **in** x:
**if** i[‘job’] **==** ‘Director’:
**return** i[‘name’]
credits[‘crew’]**=**credits[‘crew’]**.**apply(director)
credits**.**rename(columns**=**{‘crew’:‘director’},inplace**=**True)
*#合并数据集,方便清洗*full**=**pd**.**concat([movies,credits],axis**=**1)
**print**(‘合并后的数据集:‘,full**.**shape)
合并后的数据集: (4803, 24)`
2.2 查看数据集信息
*#查看数据*``full``**.**``head()
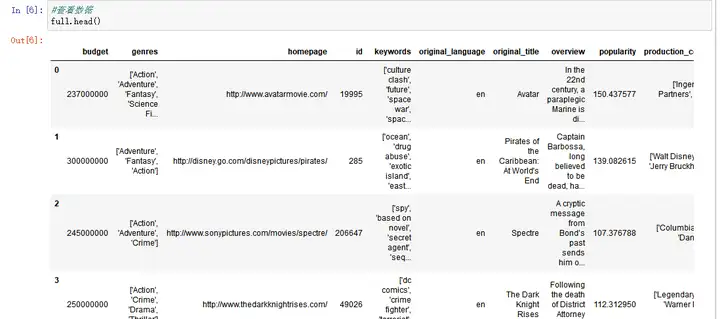
这里列出每列的含义:
- id:标识号
- imdbid:IMDB 标识号popularity:在 Movie Database 上的相对页面查看次数budget:预算(美元)**revenue:收入(美元)**originaltitle:电影名称cast:演员列表,按 | 分隔,最多 5 名演员homepage:电影首页的 URLdirector:导演列表,按 | 分隔,最多 5 名导演tagline:电影的标语keywords:与电影相关的关键字,按 | 分隔,最多 5 个关键字overview:剧情摘要runtime:电影时长genres:风格列表,按 | 分隔,最多 5 种风格productioncompanies:制作公司列表,按 | 分隔,最多 5 家公司**releasedate:首次上映日期votecount:评分次数**voteaverage:平均评分releaseyear:发行年份**budgetadj:根据通货膨胀调整的预算(2010 年,美元)revenue_adj:根据通货膨胀调整的收入(2010 年,美元)
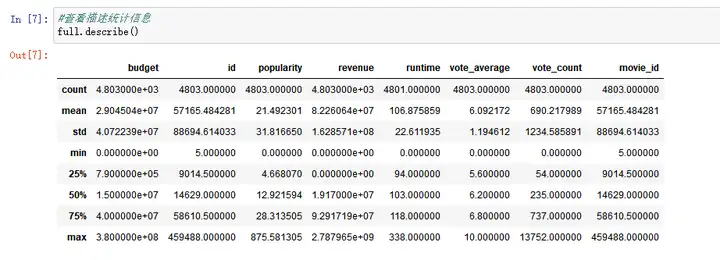
*#查看描述统计信息*``full``**.**``describe()
*#查看数据类型,总和*``full``**.**``info() ``**<**``**class**`` '``**pandas**``**.**``core``**.**``frame``**.**``DataFrame'> RangeIndex: 4803 entries, 0 to 4802 Data columns (total 24 columns): budget 4803 non``**-**``null int64 genres 4803 non``**-**``null object homepage 1712 non``**-**``null object id 4803 non``**-**``null int64 keywords 4803 non``**-**``null object original_language 4803 non``**-**``null object original_title 4803 non``**-**``null object overview 4800 non``**-**``null object popularity 4803 non``**-**``null float64 production_companies 4803 non``**-**``null object production_countries 4803 non``**-**``null object release_date 4802 non``**-**``null object revenue 4803 non``**-**``null int64 runtime 4801 non``**-**``null float64 spoken_languages 4803 non``**-**``null object status 4803 non``**-**``null object tagline 3959 non``**-**``null object title 4803 non``**-**``null object vote_average 4803 non``**-**``null float64 vote_count 4803 non``**-**``null int64 movie_id 4803 non``**-**``null int64 title 4803 non``**-**``null object cast 4803 non``**-**``null object director 4773 non``**-**``null object dtypes: float64(3), int64(5), object(16) memory usage: 900.6``**+**`` KB
根据上面的结果,我们发现数据总共有4803行。缺失数据如下:
- 数据类型:
- runtime: 缺失2条数据
- 字符类型:
- homepage: 只有1712条数据,缺失比率较大
- overview: 缺失3条数据
- release_date: 缺失1条数据
- tagline: 缺失844条数据
3. 数据清洗
3.1 数据预处理
缺失值处理
参考下面的处理方法:
-
如果是数值类型,用平均值取代
-
如果是分类数据,用最常见的类别取代
-
使用模型预测缺失值,例如:K-NN
处理数据类型:runtime
full['runtime']``**=**``full['runtime']``**.**``fillna(full['runtime']``**.**``mean())
处理字符串列:
- 缺失数据较少的,用最常见的数据取代,如:overview, release_date
- 缺失较多,用“U”补充,如:homepage, tagline根据实际情况,overview是对电影的简介,无法用最常见的数据代替,因为不同电影的介绍不一样,这里直接用“U”代替。
*#查看overview数据信息*``full['overview']``**.**``head() 0 In the 22nd century, a paraplegic Marine ``**is**`` di``**...**``1 Captain Barbossa, long believed to be dead, ha``**...**``2 A cryptic message ``**from**`` Bond’s past sends him o``**...**``3 Following the death of District Attorney Harve``**...**``4 John Carter ``**is**`` a war``**-**``weary, former military ca``**...**``Name: overview, dtype: object ``*#用缺失值填充 overview*``full['overview']``**=**``full['overview']``**.**``fillna('U') ``*#查看release_date数据信息*``full['release_date']``**.**``head() 0 2009``**-**``12``**-**``10 1 2007``**-**``05``**-**``19 2 2015``**-**``10``**-**``26 3 2012``**-**``07``**-**``16 4 2012``**-**``03``**-**``07 Name: release_date, dtype: object ``*#找出最常见变量*``full['release_date']``**.**``value_counts() 2006``**-**``01``**-**``01 10 2002``**-**``01``**-**``01 8 1999``**-**``10``**-**``22 7 2013``**-**``07``**-**``18 7 2014``**-**``12``**-**``25 7 2004``**-**``09``**-**``03 7 2011``**-**``09``**-**``16 6 2005``**-**``09``**-**``16 6 2015``**-**``10``**-**``16 6 2011``**-**``09``**-**``30 6 2003``**-**``01``**-**``01 6 2007``**-**``01``**-**``01 6 2005``**-**``01``**-**``01 6 2011``**-**``02``**-**``11 5 2006``**-**``08``**-**``11 5 2014``**-**``09``**-**``10 5 2001``**-**``09``**-**``07 5 2009``**-**``01``**-**``01 5 2015``**-**``10``**-**``02 5 2014``**-**``04``**-**``16 5 1998``**-**``12``**-**``25 5 2006``**-**``09``**-**``09 5 2010``**-**``01``**-**``01 5 1999``**-**``10``**-**``08 5 2004``**-**``12``**-**``17 5 2002``**-**``12``**-**``13 5 2011``**-**``09``**-**``09 5 2001``**-**``10``**-**``05 5 2008``**-**``10``**-**``03 5 2009``**-**``09``**-**``11 5 ``**..**``2011``**-**``06``**-**``24 1 1978``**-**``10``**-**``25 1 2013``**-**``05``**-**``21 1 1999``**-**``05``**-**``19 1 2008``**-**``06``**-**``04 1 1982``**-**``12``**-**``16 1 2003``**-**``04``**-**``23 1 2010``**-**``02``**-**``18 1 2016``**-**``05``**-**``03 1 1997``**-**``11``**-**``07 1 2008``**-**``01``**-**``15 1 2012``**-**``09``**-**``11 1 1994``**-**``11``**-**``17 1 2011``**-**``02``**-**``22 1 1981``**-**``03``**-**``17 1 2011``**-**``04``**-**``07 1 1990``**-**``04``**-**``27 1 2014``**-**``11``**-**``15 1 1993``**-**``09``**-**``30 1 1984``**-**``02``**-**``16 1 1986``**-**``10``**-**``05 1 2001``**-**``07``**-**``17 1 2015``**-**``04``**-**``24 1 1992``**-**``05``**-**``01 1 1997``**-**``04``**-**``25 1 1993``**-**``07``**-**``23 1 2015``**-**``12``**-**``24 1 2010``**-**``02``**-**``05 1 1999``**-**``01``**-**``01 1 2013``**-**``06``**-**``13 1 Name: release_date, Length: 3280, dtype: int64 ``*#从计数结果,2006-01-01最多,进行填充*``full['release_date']``**=**``full['release_date']``**.**``fillna('2006-01-01') ``*#对缺失数据较多的homepage, tagline用“U”进行填充*``full['homepage']``**=**``full['homepage']``**.**``fillna('U') full['tagline']``**=**``full['tagline']``**.**``fillna('U')
3.2 特征提取
3.2.1 数据分类
对不同数据类型的特征提取方法:
- 数值类型:直接使用
- 时间序列:转换成单独的年、月、日
- 分类数据:用数值代替类别,one-hot编码 分类如下:
- 数值类型:
- budget, popularity, revenue, runtime,vote_average, vote_count
- 时间序列:
- releasedate
- 分类数据:
- 有类别:original_language, production_companies, production_countries, spokenlanguages, status, cast
- 字符串:genres, homepage, id, original_title, keywords, overview, tagline, title, movie_id, crew
3.2.1.1 时间序列
full["release_date"]``**=**``pd``**.**``to_datetime(full["release_date"],format``**=**``'%Y-%m-%d') ``*#提取电影年份*``years``**=**``[] ``**for**`` x ``**in**`` full['release_date']: year``**=**``x``**.**``year years``**.**``append(year) Years``**=**``pd``**.**``Series(years) full['year']``**=**``Years full['year']``**.**``head() 0 2009 1 2007 2 2015 3 2012 4 2012 Name: year, dtype: int64
3.2.1.2 分类数据:字符串
对genres进行提取
full['genres']``**=**``full['genres']``**.**``str``**.**``strip('[]')``**.**``str``**.**``replace(' ','')``**.**``str``**.**``replace("'",'') full['genres']``**=**``full['genres']``**.**``str``**.**``split(',') list1``**=**``[] ``**for**`` i ``**in**`` full['genres']: list1``**.**``extend(i) genres``**=**``pd``**.**``Series(list1)``**.**``value_counts()``**.**``sort_values(ascending``**=**``False) genres[:10] genres``**=**``pd``**.**``DataFrame(genres[:10]) genres
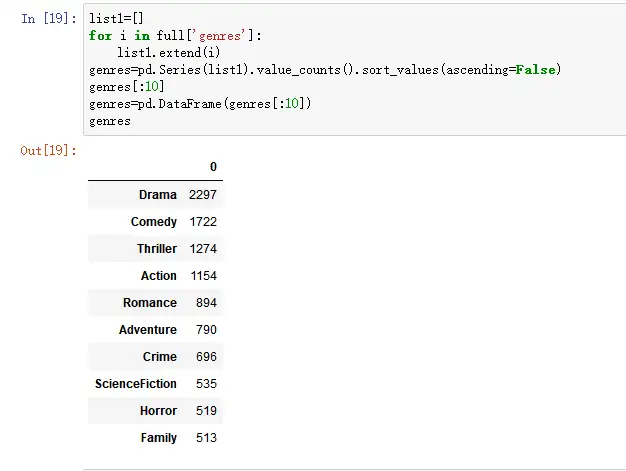
*#更改列名*``genres``**.**``rename(columns``**=**``{0:"total"},inplace``**=**``True)
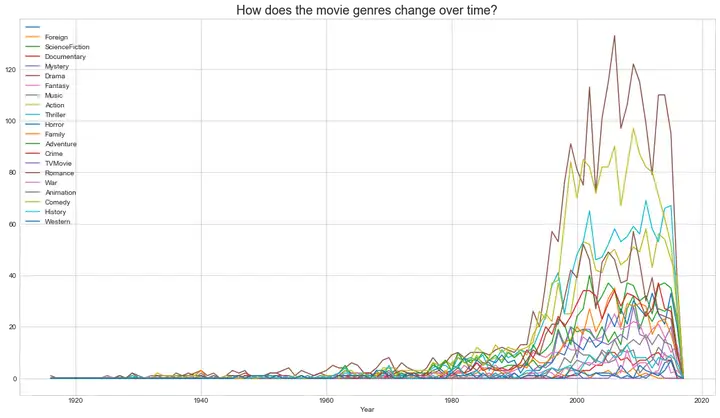
问题1:电影类型是如何随着时间的推移发生变化的?
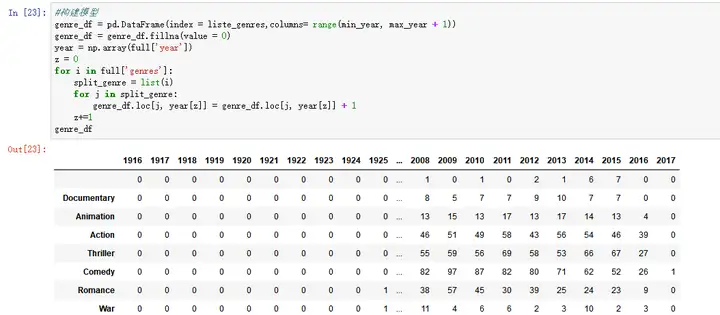
min_year ``**=**`` full['year']``**.**``min() max_year ``**=**`` full['year']``**.**``max() ``*#提取电影风格*``liste_genres ``**=**`` set() ``**for**`` s ``**in**`` full['genres']: liste_genres ``**=**`` set()``**.**``union(s, liste_genres) liste_genres ``**=**`` list(liste_genres) ``*#构建模型*``genre_df ``**=**`` pd``**.**``DataFrame(index ``**=**`` liste_genres,columns``**=**`` range(min_year, max_year ``**+**`` 1)) genre_df ``**=**`` genre_df``**.**``fillna(value ``**=**`` 0) year ``**=**`` np``**.**``array(full['year']) z ``**=**`` 0 ``**for**`` i ``**in**`` full['genres']: split_genre ``**=**`` list(i) ``**for**`` j ``**in**`` split_genre: genre_df``**.**``loc[j, year[z]] ``**=**`` genre_df``**.**``loc[j, year[z]] ``**+**`` 1 z``**+=**``1 genre_df
*#可视化折线图*``plt``**.**``figure(figsize``**=**``(18,10)) plt``**.**``plot(genre_df``**.**``T) plt``**.**``xlabel('Year') plt``**.**``title('How does the movie genres change over time?',fontsize``**=**``18) plt``**.**``legend(genre_df``**.**``T) plt``**.**``show()
哪些电影类型最多
`f,ax**=**plt**.**subplots(figsize**=**(12,10))
g**=**sns**.**barplot(y**=**genres**.**index,x**=**”total”,data**=**genres,palette**=**”pastel”,ax**=**ax)
*# 设置刻度字体大小*plt**.**xticks(fontsize**=**15)
plt**.**yticks(fontsize**=**15)
plt**.**ylabel(“Genres”,fontsize**=**15)
plt**.**xlabel(“Count”,fontsize**=**15)
plt**.**title(‘Which is the most popular movie genres?‘,fontsize**=**15)
**<**matplotlib**.**text**.**Text at 0x26689156e80“>`
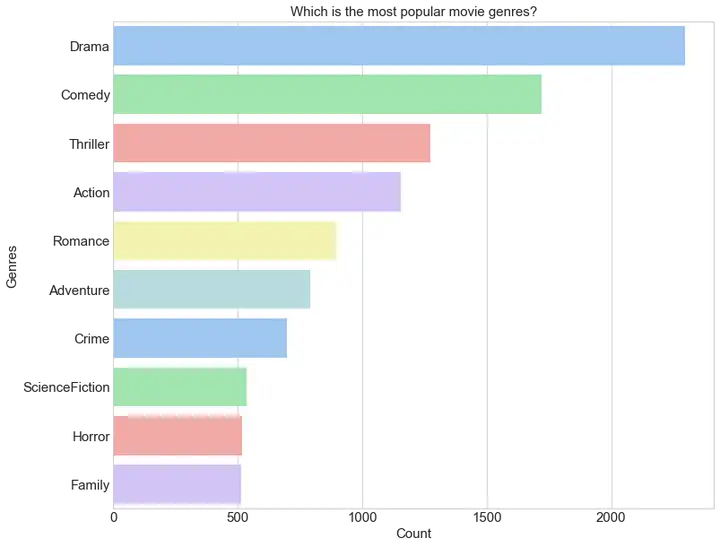
从图中我们可以看出,上世纪90年代到2000年,电影市场经历了迅猛发展的时期,一些风格鲜明的电影持续保持着活力,并一直出现在大众的视野中。其中,戏剧、喜剧和惊悚片最为明显,客户的接受程度更高。如果拍摄新的电影,可以从这几种风格中选择,降低了票房低的风险。
问题2:Universal Pictures和Paramount Pictures之间的对比情况如何?
**for**`` i ``**in**`` full['production_companies']: ``**if**`` 'Paramount Pictures' ``**in**`` i: i``**=**``'Paramount Pictures' ``**elif**`` 'Universal Pictures' ``**in**`` i: i``**=**``'Universal Pictures' ``**else**``: i``**=**``'' full['production_companies']``**=**``full['production_companies']``**.**``str``**.**``strip('[]')``**.**``str``**.**``replace("'",'') ``*#筛选两家公司的数据*``parDf``**=**``full``**.**``loc[full['production_companies']``**==**``'Paramount Pictures'] uniDf``**=**``full``**.**``loc[full['production_companies']``**==**``'Universal Pictures'] ``*#建立模型*``com_gen_df``**=**``pd``**.**``DataFrame(index``**=**``liste_genres,columns``**=**``['Paramount','Universal']) com_gen_df``**=**``com_gen_df``**.**``fillna(value``**=**``0) ``**for**`` i ``**in**`` parDf['genres']: split_genre``**=**``list(i) ``**for**`` j ``**in**`` split_genre: com_gen_df``**.**``loc[j,'Paramount']``**=**``com_gen_df``**.**``loc[j,'Paramount']``**+**``1 ``**for**`` i ``**in**`` uniDf['genres']: split_genre``**=**``list(i) ``**for**`` j ``**in**`` split_genre: com_gen_df``**.**``loc[j,'Universal']``**=**``com_gen_df``**.**``loc[j,'Universal']``**+**``1 com_gen_df``**.**``head()
*#选取排名前10的电影类型*``com_gen_df``**=**``com_gen_df``**.**``sort_values(by``**=**``'Paramount',ascending``**=**``False) Par_gen_df``**=**``com_gen_df``**.**``iloc[0:9] com_gen_df``**=**``com_gen_df``**.**``sort_values(by``**=**``'Universal',ascending``**=**``False) Uni_gen_df``**=**``com_gen_df``**.**``iloc[0:9] fig``**=**``plt``**.**``figure('Paramount VS Universal',figsize``**=**``(13,6)) ax``**=**``fig``**.**``add_subplot(121) ax``**.**``set_title('Paramount TOP 10') ax``**.**``pie(x``**=**``Par_gen_df['Paramount'],labels``**=**``Par_gen_df``**.**``index,shadow``**=**``True,autopct``**=**``'%1.1f%%',labeldistance``**=**``1.1,startangle``**=**``90,pctdistance``**=**``0.6) ax``**=**``fig``**.**``add_subplot(122) ax``**.**``set_title('Universal TOP 10') ax``**.**``pie(x``**=**``Uni_gen_df['Universal'],labels``**=**``Uni_gen_df``**.**``index,shadow``**=**``True,autopct``**=**``'%1.1f%%',labeldistance``**=**``1.1,startangle``**=**``90,pctdistance``**=**``0.6) plt``**.**``show()
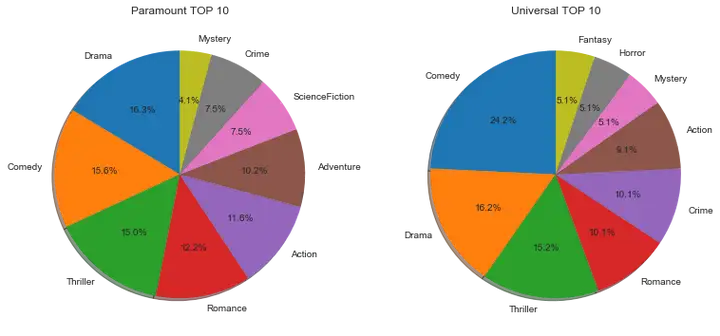
fig ``**=**`` plt``**.**``gcf() fig``**.**``set_size_inches(18.5, 10.5) com_gen_df``**.**``plot(kind``**=**``'bar') plt``**.**``title('Paramount TOP 10') plt``**.**``show() ``**<**``matplotlib``**.**``figure``**.**``Figure at 0x2668aa3e198``**>**
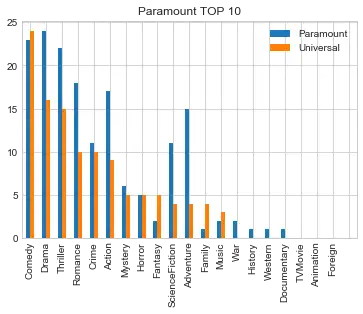
两家电影公司发行的电影风格大致一致,主要是喜剧、戏剧、动作片等等。而从发行量来看,Paramount总体比Universal多。但喜剧的发行量,Universal公司稍稍领先。
问题3:改编电影和原创电影的对比情况如何?
a``**=**``'based on novel' full['if_original']``**=**``full['keywords']``**.**``str``**.**``contains(a)``**.**``apply(``**lambda**`` x: 'no_original' ``**if**`` x ``**else**`` 'original') key_count``**=**``full['if_original']``**.**``value_counts() plt``**.**``figure(figsize``**=**``(6,6)) plt``**.**``title('Adaptation Film VS Original Film') plt``**.**``pie(x``**=**``key_count,labels``**=**``key_count``**.**``index,labeldistance``**=**``1.1,autopct``**=**``'%1.1f%%') plt``**.**``show()
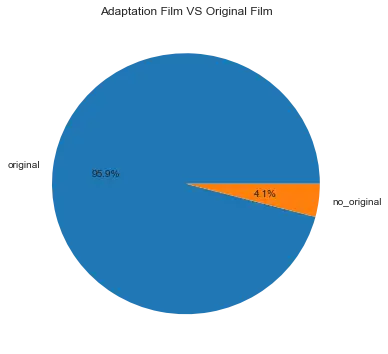
可以看的出,市场上很大部分是原创电影,改编电影只占很小的部分。这里有两种思考:第一种是可以顺应顺应市场的发展做原创电影。第二是积极尝试竞争更小的改编电影,也是一种市场策略。
问题4: 评分次数与电影收入的相关关系如何?
*#相关系数表*``full``**.**``corr()
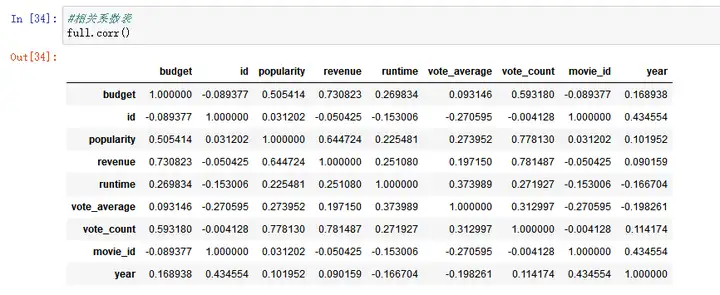
*#建立模型 vote_count与revenue的相关系数0.78*``x``**=**``full['vote_count'] y``**=**``full['revenue'] ``*#拆分训练数据和测试数据*``**from**`` sklearn.cross_validation ``**import**`` train_test_split x_train, x_test, y_train, y_test``**=**``train_test_split(x,y,train_size``**=**``0.8) plt``**.**``scatter(x_train,y_train,color``**=**``'blue',label``**=**``'train') plt``**.**``scatter(x_test,y_test,color``**=**``'red',label``**=**``'test') plt``**.**``xlabel('vote_count',fontsize``**=**``12) plt``**.**``ylabel('revenue',fontsize``**=**``12) plt``**.**``legend(loc``**=**``2) plt``**.**``show()
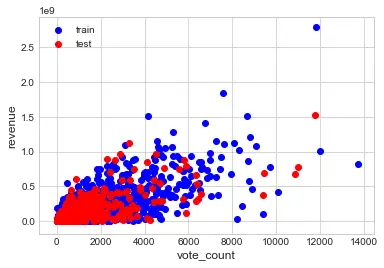
*#导入模型*``**from**`` sklearn.linear_model ``**import**`` LinearRegression x_train``**=**``x_train``**.**``values``**.**``reshape(``**-**``1,1) x_test``**=**``x_test``**.**``values``**.**``reshape(``**-**``1,1) trainmodel``**=**``LinearRegression() trainmodel``**.**``fit(x_train,y_train) LinearRegression(copy_X``**=**``True, fit_intercept``**=**``True, n_jobs``**=**``1, normalize``**=**``False) ``*#最佳拟合线*``a``**=**``trainmodel``**.**``intercept_ b``**=**``trainmodel``**.**``coef_ ``**print**``(a,b) 10079735.5674 [ 105896.53153847] ``*#绘图*``plt``**.**``scatter(x_train,y_train,color``**=**``'blue',label``**=**``'train') y_train_pred``**=**``trainmodel``**.**``predict(x_train) plt``**.**``plot(x_train,y_train_pred,color``**=**``'black',label``**=**``'best lines') plt``**.**``xlabel('vote_count',fontsize``**=**``12) plt``**.**``ylabel('revenue',fontsize``**=**``12) plt``**.**``legend(loc``**=**``1) plt``**.**``show()
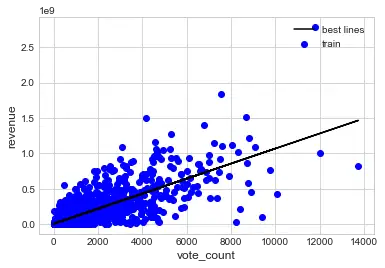
*#评估模型*``trainmodel``**.**``score(x_test,y_test) 0.56092036104853049
从以上模型,可以看出评分次数和电影收入存在线性相关,且模型准备度好。
经过以上的数据分析,我们给出客户的建议如下:
- 从风格来看,可以选择喜剧片,受众较广,票房低迷的概率较低。对于新公司有一定的收入保证,是一种比较稳妥的市场策略。
- 从题材来说,如果有好的剧本,可以拍摄原创电影。如果剧本一般,且演员知名度较低的话,可能不会引起很大的市场反响,因为市场上绝大部分是原创电影,竞争比较激烈。如果从市场接受度来考虑,可以尝试改编电影。这类电影本身拥有一定的接受度,同时加上新的改编,会让人耳目一新,容易成为热点话题,为新创公司引来流量。
- 从评分次数和电影收入线性相关来看,一旦电影上映,可以采取营销手段,鼓励观众去给电影打分。也可以雇用水军,为电影提供好评。评分次数增多,会为新观众观看电影打下基础,这样事半功倍。